
Softwarový gigant Facebook již před mnoha lety dosáhl velikosti, kdy by jen těžko využíval standardní cloudové hostingové služby jako AWS od Amazonu nebo Azure od Microsoftu, a tak své služby provozuje ve vlastních datových centrech. A ne ledajakých – postaveny jsou podle standardu Open Compute Project, jehož je Facebook spoluautorem.
„Doma“ vyvinuté jsou podle vyjádření některých zaměstnanců Facebooku pro server Verge také interní systémy společnosti. Což se, jak si níže vysvětlíme, během pondělního výpadku ukázalo jako dost problematické.
„V 15.51 UTC jsme otevřeli interní incident s názvem Facebook DNS lookup returning SERVFAIL, protože jsme se obávali, že něco není v pořádku s naším DNS resolverem 1.1.1.1,“ uvedli specialisté Celso Martinho a Tom Strickx na blogu společnosti Cloudflare, která datacentrům Facebooku zajišťuje konektivitu. „Ukázalo se však, že se děje něco mnohem vážnějšího. Facebook a jeho přidružené služby WhatsApp a Instagram byly skutečně nefunkční. Jejich názvy DNS se přestaly překládat a jejich infrastrukturní IP adresy byly nedostupné. Bylo to, jako by někdo najednou ‚vytáhl kabely‘ z jejich datových center a odpojil je od internetu,“ vysvětlují.
Chybná aktualizace konfigurace páteřních síťových prvků v datacentru způsobila nefunkčnost takzvaného BGP, tedy Border Gateway Protocol. To je – velmi zjednodušeně řečeno – systém, který se stará o propojení různých autonomních částí internetové sítě (například síť datového centra nebo síť poskytovatele internetového připojení), respektive vytváří navigační pokyny, podle kterých se mezi nimi data přenášejí. Jakmile nefunguje BGP, je to, jako byste datům vypnuli navigaci.
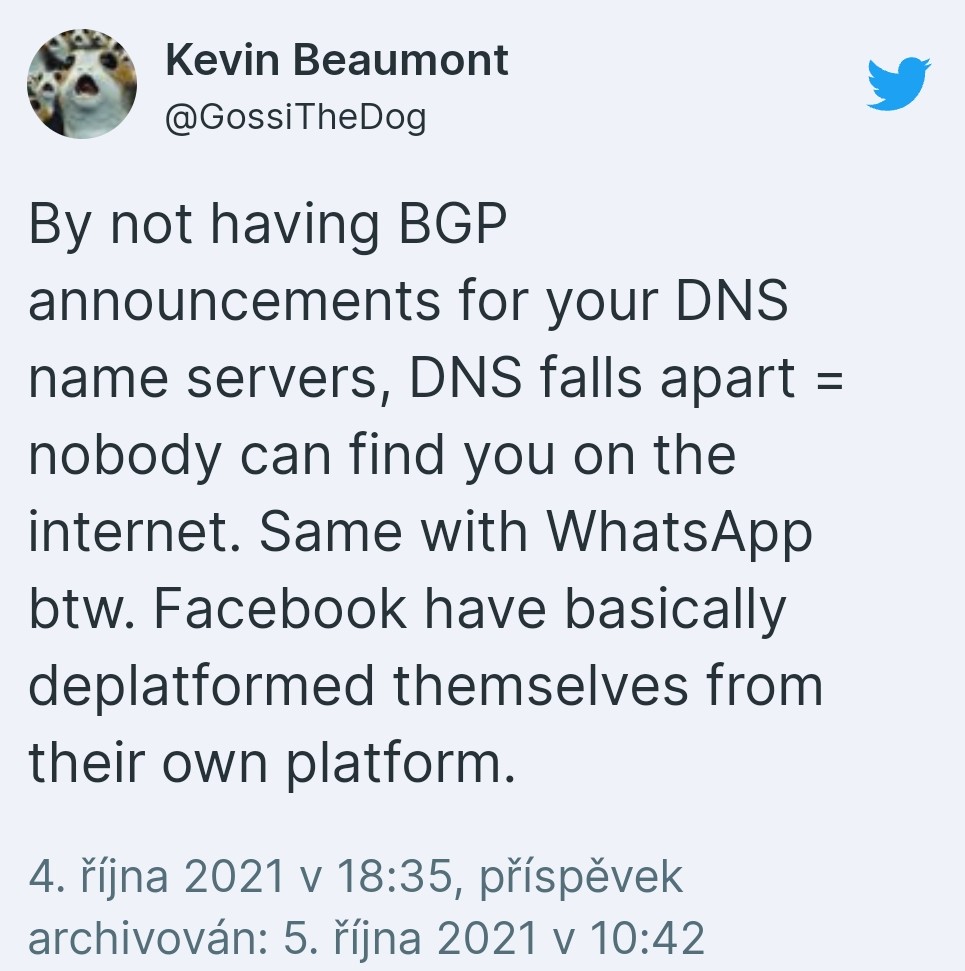
Stručně to tweetnul Kevin Beaumont, bývalý šéf bezpečnosti společnosti Microsoft: „Pokud nemáte oznámení BGP pro své jmenné servery DNS, DNS se rozpadne = nikdo vás na internetu nenajde. Facebook se v podstatě odstranil z vlastní platformy.“ To je důvod, proč Facebook, WhatsApp a Instagram uživatelům nefungovaly.
O něco překvapivější je důvod, proč trvalo několik hodin, než se podařilo provoz služeb obnovit. Na stejné infrastruktuře totiž fungují i interní systémy společnosti. Zaměstnance tak porucha v podstatě paralyzovala. Nefunkční totiž byly nejen firemní komunikační nástroje, ale – jak tweetnula reportérka The New York Times Sheera Frenkelová – třeba i systém autorizace zaměstnanců pro vstup do dveří.
Zaměstnanci tak v týmech postupně přecházeli na konkurenční komunikační platformy. Ještě větší problém měli technici, kteří neměli vzdálený přístup k systémům v datacentrech, a proto nemohli začít s diagnostikou problému a jeho odstraněním. Ono „vytažení kabelů“ totiž neměli jak obejít. Museli tedy do postižených datacenter fyzicky dojet, dostat se dovnitř a vše opravit pomocí lokálního přístupu.
Jako by toho nebylo málo, začaly se na zbývajících sociálních sítích množit i stížnosti na pomalé či vypadávající internetové připojení. Světlo do zmatku vnesl například tweet Johna Grahama-Cumminga, technického ředitele společnosti Cloudflare.
„Teď přijde ta zábavná část. Cloudflare provozuje bezplatný DNS resolver 1.1.1.1 a spousta lidí ho používá. Takže když je Facebook atd. mimo provoz… Hádejte, co se stane? Lidé to zkoušejí znovu. Aplikace to zkoušejí znovu. Míří k nám obrovská záplava DNS provozu, který žádá o facebook.com,“ stojí ve výše uvedeném tweetu.




Napsat komentář